Human-Robot interactions with Apollo: Making-Of
7th October 2017
People have been asking for implementation details on this demo:
Here I explain it all. This post is meant for experienced roboticists interested in implementing something similar on their favorite robot.
The hardware
Apollo is a fixed-base manipulation platforms equipped with 7-DoF Kuka LWR IV arms, three fingered Barrett Hands and a RGB-D camera (Asus Xtion) mounted on an active humanoid head (Sarcos). Each finger of the hand is equipped with touch and strain sensors. In this demo, for vision, we use exclusively the xtion. We also have a vicon tracking system in the lab, but I did not use it.The eyes also are embedded with some stereo vision cameras, but I also did not use those (eyes motions are there only to make the robot look lively). The mouth is an array of LEDs under the 3d printed head case.
Software stack overview
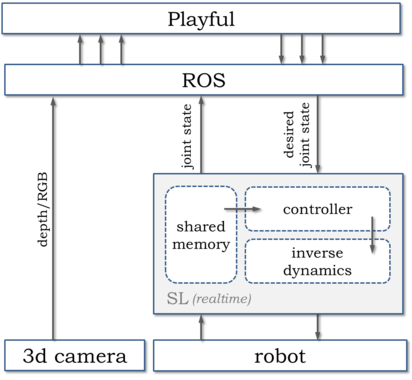
Real-time controllers (running on xenomai patched ubuntu) interface with ROS via ROS-Realtime. ROS is used to get data from the xtion (usual openni2) and do processing of the RGB point cloud (using PCL).TF is used for managing the transforms. The top layer, Playful, is the behavior specification software, i.e. where desired joint values and velocity are computed such as resulting in robot motions that correspond to the desired behavior. The software is grandly simplified by the design choice of running local motion optimization technics, as opposed to global technics based on generation of optimal trajectories of the full kinematic chain.
Realtime controllers
All the actuators (of the hand, the head and the head) are interfaced with SL, which is our "universal" real time robot controller software. SL is what we used for realtime control of all our robots (Hermes, Athena, Arm and others). An instance of SL is a mix of code which is robot independant (e.g. for dumping data, using realtime safe shared memory, computing inverse dynamics, etc), robot specific (to interface with the robot specific hardware and apply suitable controllers) and code which is application specific. Application specific code are implemented in tasks, which should computes at each control loop the desired joint states (in terms of position, velocity and acceleration). Rest of SL ensures these desired states are applied. In the case of Apollo, the controllers for applying the desired states are complient, which is required for security reasons. You may see the robotic arm is moved when pushed:
ROS interface
As stated above, SL provides realtime controllers which can apply any (reasonable) desired joint states, joint states which need to be specified in a task. Tasks can implement any arbitrary (realtime safe) code. To interface with ROS, we created a task which 1) instantiates a realtime ROS publisher which sends the current joint state to the rest of the world, and 2) instantiates a real-time subscriber which receives desired joint states. Broadcasting joint states on the "joint_states" topic allows to put in place the usual ROS machinery, including the usage of TF and RVIZ (as we do have a URDF model of the robot). The subscriber allows the desired joint states to be computed and published from any arbitrary node, including python higher level controllers. The obvious limitation of using Python for computing desired joint states is that, since computation will be performed from a non-realtime environment, these joint states will be limited to desired position and velocity (i.e. not torque). This is ok for a lots of applications, including the interactive behavior we had in mind.
Local motion generation
Back to the realtime task in SL. This tasks receives via ROS realtime desired joint position and velocity. I added to it code for computing for each desired joint state a nice torque profile which would ensure a smooth acceleration profile is applied (i.e. minimisation of jerk).
If you are following, you may have noticed that the realtime task does not receive a desired joints trajectory, just a desired joint state. So the torque profile is not computed such as executing a trajectory, but such as minimizing jerk while transitioning between the current joint state to the new desired joint state. This could have been problematic: for our application, the desired joint state (as published by Python controllers) will be updated at a frequency of around 30Hz (frequency of the xtion). Thus, the jerk minimizing acceleration profile is to be recomputed at 30Hz, often before the previously desired joint state could be reached. Thus, we face the tricky situation that more often than not, the controllers do not have the chance to apply computed torque profile completely, each profile being "overwritten" at 30Hz. Luckily, this tricky part turns out not to be tricky. It seems that even when the torque profile is recomputed at any arbitrary frequency (in our case 30Hz), the applied acceleration profile remains smooth. Maybe there is some mathematical proof showing that if you overwrite at a certain frequency a jerk optimal motion with another jerk optimal motion, you end up with a jerk optimal motion. But I did not look into this.
Some of you may feel that all the above is just unimportant implementation details. But in my opinion it explains a big deal about the reactivity of the final behavior. We switched from A) computation of trajectories to be applied by the realtime level to B) applying desired joint states which may be updated at any arbitrary frequency. This simplifies the code of the realtime task a lot (reduced to around 100 lines of code), while making trivial the implementation of reactivity at the higher level: the higher level does not need to generate/track/overwrite/preempt trajectories. Instead, it publishes whatever joint state it considered suitable at the current iteration (with no memory of the previous iteration or expectation about the next iteration). Careful readers will object that not relying on trajectories destroys the possibility of applying any serious motion optimization. This is correct. But we can still use rapid and reactive local motion generation techniques which are suitable for the behavior at hand. Details somewhere below.
NaoQi, the middleware from Softbank robotics/Aldebaran, inspired all this. I developed things this way so that at the higher python level I could replicate the "non blocking" API they provide for Nao (in the motion proxy) and that I have been using for years, for example here:
I always though this idea of non blocking functions was awesome, and I am happy to see it applied beyond Nao or Pepper.
Perception
We needed to detect using the head mounted xtion: the blue cup, the red cup, people's hands and people's heads. Those of you who where hoping to read here something interesting about advanced perception will be disappointed. What I implemented is basic and simple. However, if you are a "half full glass" kind of person, you may be happy to see that simple PCL based algorithms can do a good trick in giving the illusion the robot understands what is going on around it.
Detection of the blue and read cup is based on simple color filtering in the YUV space. I made a cute opencv interface which allows me to click on the color I'd like to be detected, and cups are detected in RGB point clouds based on those. From the color filtered point clouds, suitable grasping points are generated.
For detection of head and hand, simple clustering of the point cloud is applied, and the robot considers that any "blob" in front of the table is a person, and any "blob" above the table which is not a cup is a hand. The code is trivial. All this works quite ok in regards of the hand and head detection. I am quite unhappy with the color based detection of the cup. This is not very robust to changes in luminosity (even though I use the YUV space), and I do not find it satisfactory to ask people not to wear blue or red clothes.
For my next work, I plan to use state of the art object tracking. One of the modern library has been developped in our lab (details here). These library would not work out of the box, though. Reason is that 1) trackers need to be initialized and 2) the dynamic behavior I am interested in involve the robot looking alternatively at various objects. Thus, tracked objects go in and out the field of vision: the trackers will need to be constantly reinitialized. And it is not that trivial to get suitable priors on moving objects which are out of sight. I guess such priors can nevertheless be generated somehow from applying some object detection algorithm on the 2d image. Naive me thinks it should not be too complicated. We will see ...
Inverse kinematics
I reused the software based on coordinate descent I developed when working on Nao. Nao is underactuaed, but it also worked for Apollo, which is overactuated. I assume any iterative method based on the jabobian would also have worked. The reason I use coordinate descent is because at its core it is based on a score function. The obvious function to use is the distance between current 6d position of the end effector and the desired 6d position. But the function can be arbitrarly changed to anything, which is a feature I plan to use in the near future.
Inverse kinematics for head tracking if object of interest (head, hands, cup) is trivial, and was done the usual way.
Arm tracking for intrasinc calibration
Runtime intrinsic calibration of the kuka arms is set to run by default on Apollo. This corrects the transforms between the xtion and the other robot frames using visual tracking, resulting in millimiter precision on end-effector position estimation. Since the demo only needs centimeter precision, I am not sure this made a significant difference. But it was running in the background, so I want to give credit to the authors of this system. Here is the video presentation:
Grasp
The closing of the hand has nothing special. When asked to close, the hand do so until a certain strain is detected. This safety measure ensures the robot will not put too much force in its grasp. Which is critical for security. You can see why in this video (one of our guest spontaneously did that):
The touch sensors are used to keep the rest of the system informed if the robot currently has something in its hand or not.
End-effector motion generation
If required, the end-effector performs some "obstacle avoidance" around objects. For example here for moving the blue cup above the red cup:
The code for doing so is trivial and based on simple 3d geometry. A virtual sphere is created around the obstacle (here the blue cup). The final target point on this sphere is first computed. This point corresponds to the position on the sphere the end-effector should be at for smooth grasp. Then the "instant" target point is computed. This point on the sphere is the closest to the final target point the robot can reach without bumping on the cup. At each iteration (i.e. at 30Hz), the positions of the sphere, the final target point and the instant target point are recomputed, and the instant target point is fed to the inverse kinematics. The final results is rapid and reactive:
Obvious limitation is that this system does not look into the future and would not scale to more complicated scenarios in which several objects should be avoided (e.g. it does not try to avoid the user's arms).
Behavior building
From the above, we have the main "building blocks" for creating the target dynamic behavior: perception, grasp and motion generation. Using ROS and python (including the possibility to publish any desired states), developing a few other higher level primitives for random motions (of the head, the eyes and the hand), mouth expression and table avoidance is trivial. What remains to be done is the "orchestration", i.e. the parametrized call to these primitives such that the desired lively behavior is obtained. We used for this Playful, which is a novel scripting language that I developped to support exactly this. I am in the process of publishing Playful, so I can not give to much details on that part now. Only this higher level description:
Yes, but why ?
The final goal of this project was not to get the robot playing with cups. It was rather to develop a versatile software stack that would allow us to rapidly create new original robot applications. Everything described above is implemented in a quite modular fashion, and it would be often straightforward to replace or add modules. We could for example throw some motion capture dats into the mix. Also, the orchestration software we use (Playful), allows us to rapidly change the behavior applied by the robot, and even to create new ones. Apollo is now a convenient plateform for the study of human-robot interactions, as we could create rapidly any (reasonable and realistic) application researchers with expertize in social science would like use for their study.